mirror of
https://github.com/vale981/ray
synced 2025-03-07 02:51:39 -05:00
61 lines
No EOL
3.7 KiB
Markdown
61 lines
No EOL
3.7 KiB
Markdown
(serve-handle-explainer)=
|
||
|
||
# ServeHandle: Calling Deployments from Python
|
||
|
||
[ServeHandle](serve-key-concepts-query-deployment) allows you to programmatically invoke your Serve deployments.
|
||
|
||
This is particularly useful for two use cases when:
|
||
- calling deployments dynamically within the deployment graph.
|
||
- iterating and testing your application in Python.
|
||
|
||
To use the ServeHandle, use {mod}`handle.remote <ray.serve.handle.RayServeHandle.remote>` to send requests to a deployment.
|
||
These requests can be ordinary Python args and kwargs that are passed directly to the method. This returns a Ray `ObjectRef` whose result can be waited for or retrieved using `await` or `ray.get`.
|
||
|
||
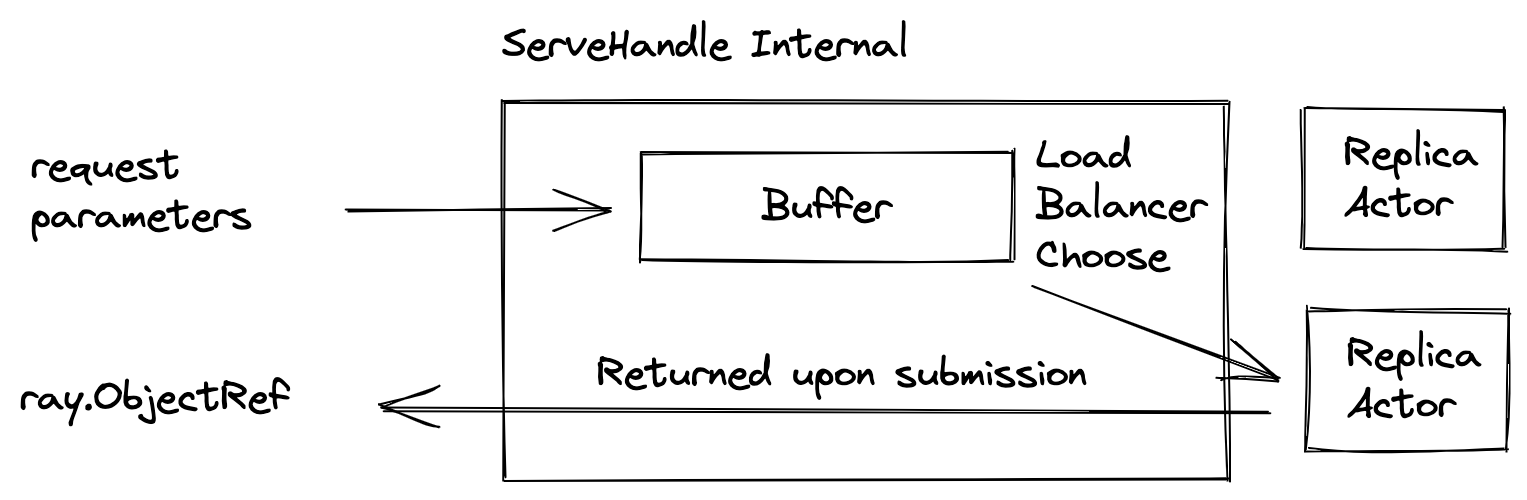
Conceptually, ServeHandle is a client side load balancer, routing requests to any replicas of a given deployment. Also, it performs buffering internally so it won't overwhelm the replicas.
|
||
Using the current number of requests buffered, it informs the autoscaler to scale up the number of replicas.
|
||
|
||
|
||
|
||
ServeHandle takes request parameters and returns a future object of type [`ray.ObjectRef`](objects-in-ray), whose value will be filled with the result object. Because of the internal buffering, the time from submitting a request to getting a `ray.ObjectRef` varies from instantaneous to indefinitely long.
|
||
|
||
Because of this variability, we offer two types of handles to ensure the buffering period is handled efficiently. We offer synchronous and asynchronous versions of the handle:
|
||
- `RayServeSyncHandle` directly returns a `ray.ObjectRef`. It blocks the current thread until the request is matched to a replica.
|
||
- `RayServeDeploymentHandle` returns an `asyncio.Task` upon submission. The `asyncio.Task` can be awaited to resolve to a ray.ObjectRef. While the current request is buffered, other requests can be processed concurrently.
|
||
|
||
`serve.run` deploys a deployment graph and returns the entrypoint node’s handle (the node you passed as argument to `serve.run`). The return type is a `RayServeSyncHandle`. This is useful for interacting with and testing the newly created deployment graph.
|
||
|
||
```{literalinclude} ../serve/doc_code/handle_guide.py
|
||
:start-after: __begin_sync_handle__
|
||
:end-before: __end_sync_handle__
|
||
:language: python
|
||
```
|
||
|
||
In all other cases, `RayServeDeploymentHandle` is the default because the API is more performant than its blocking counterpart. For example, when implementing a dynamic dispatch node in deployment graph, the handle is asynchronous.
|
||
|
||
```{literalinclude} ../serve/doc_code/handle_guide.py
|
||
:start-after: __begin_async_handle__
|
||
:end-before: __end_async_handle__
|
||
:language: python
|
||
```
|
||
|
||
The result of `deployment_handle.remote()` can also be passed directly as an argument to other downstream handles, without having to await on it.
|
||
|
||
```{literalinclude} ../serve/doc_code/handle_guide.py
|
||
:start-after: __begin_async_handle_chain__
|
||
:end-before: __end_async_handle_chain__
|
||
:language: python
|
||
```
|
||
|
||
## Note about ray.ObjectRef
|
||
|
||
`ray.ObjectRef` corresponds to the result of a request submission. To retrieve the result, you can use the synchronous Ray Core API `ray.get(ref)` or the async API `await ref`. To wait for the result to be available without retrieving it, you can use the synchronous API `ray.wait([ref])` or the async API `await asyncio.wait([ref])`. You can mix and match these calls, but we recommend using async APIs to increase concurrency.
|
||
|
||
## Calling a specific method
|
||
|
||
In both types of ServeHandle, you can call a specific method by using the `.method_name` accessor. For example:
|
||
|
||
```{literalinclude} ../serve/doc_code/handle_guide.py
|
||
:start-after: __begin_handle_method__
|
||
:end-before: __end_handle_method__
|
||
:language: python
|
||
``` |