mirror of
https://github.com/vale981/ray
synced 2025-03-05 10:01:43 -05:00
[docs][serve] Trim down user guide & clean up table of contents (#27926)
An attempt at making the docs shorter and sweeter including various small cleanup items. - Reorder the TOC on the sidebar for the user guides to be more linear based on a user's journey. - Put the batching content under the performance guide. - Remove the AIR guide (AIR users already have a serving guide). - Combine the `ServeHandle` and model composition pages into a single guide. We may want to revisit this in the future but for now better to have it in a single place instead of duplicated (with links going to both). - Fix the index page for the user guides to match the TOC sidebar. - Rename a few pages for clarity & consistency. - Remove some now-redundant content (old ML models user guide).
This commit is contained in:
parent
2878119ece
commit
a400cde56f
21 changed files with 145 additions and 530 deletions
|
|
@ -168,16 +168,9 @@ parts:
|
|||
- file: serve/key-concepts
|
||||
- file: serve/user-guide
|
||||
sections:
|
||||
- file: serve/managing-deployments
|
||||
- file: serve/handling-dependencies
|
||||
- file: serve/scaling-and-resource-allocation
|
||||
- file: serve/http-guide
|
||||
- file: serve/handle-guide
|
||||
- file: serve/ray-air-serve-guide
|
||||
- file: serve/ml-models
|
||||
- file: serve/batching-guide
|
||||
- file: serve/scaling-and-resource-allocation
|
||||
- file: serve/model_composition
|
||||
- file: serve/performance
|
||||
- file: serve/dev-workflow
|
||||
- file: serve/production-guide/index
|
||||
sections:
|
||||
|
|
@ -186,6 +179,8 @@ parts:
|
|||
- file: serve/production-guide/kubernetes
|
||||
- file: serve/production-guide/monitoring
|
||||
- file: serve/production-guide/failures
|
||||
- file: serve/performance
|
||||
- file: serve/handling-dependencies
|
||||
- file: serve/managing-java-deployments
|
||||
- file: serve/migration
|
||||
- file: serve/architecture
|
||||
|
|
|
|||
|
|
@ -1,11 +1,10 @@
|
|||
(serve-architecture)=
|
||||
|
||||
# Serve Architecture
|
||||
# Architecture
|
||||
|
||||
This section should help you:
|
||||
|
||||
- Get an overview of how each component in Serve works
|
||||
- Understand the different types of actors that make up a Serve instance
|
||||
In this section, we explore Serve's key architectural concepts and components. It will offer insight and overview into:
|
||||
- the role of each component in Serve and how they work
|
||||
- the different types of actors that make up a Serve application
|
||||
|
||||
% Figure source: https://docs.google.com/drawings/d/1jSuBN5dkSj2s9-0eGzlU_ldsRa3TsswQUZM-cMQ29a0/edit?usp=sharing
|
||||
|
||||
|
|
@ -32,11 +31,11 @@ There are three kinds of actors that are created to make up a Serve instance:
|
|||
- **Replicas**: Actors that actually execute the code in response to a
|
||||
request. For example, they may contain an instantiation of an ML model. Each
|
||||
replica processes individual requests from the HTTP proxy (these may be batched
|
||||
by the replica using `@serve.batch`, see the [batching](serve-batching) docs).
|
||||
by the replica using `@serve.batch`, see the [batching](serve-performance-batching-requests) docs).
|
||||
|
||||
## Lifetime of a Request
|
||||
|
||||
When an HTTP request is sent to the HTTP proxy, the following things happen:
|
||||
When an HTTP request is sent to the HTTP proxy, the following happens:
|
||||
|
||||
1. The HTTP request is received and parsed.
|
||||
2. The correct deployment associated with the HTTP URL path is looked up. The
|
||||
|
|
@ -114,7 +113,7 @@ same node which routes requests to replicas for a deployment. When a
|
|||
request is sent from one replica to another via the handle, the
|
||||
requests go through the same data path as incoming HTTP requests. This enables
|
||||
the same deployment selection and batching procedures to happen. ServeHandles are
|
||||
often used to implement [model composition](serve-model-composition-guide).
|
||||
often used to implement [model composition](serve-model-composition).
|
||||
|
||||
### What happens to large requests?
|
||||
|
||||
|
|
|
|||
|
|
@ -1,46 +0,0 @@
|
|||
# Request Batching
|
||||
|
||||
Serve offers a request batching feature that can improve your service throughput without sacrificing latency. This is possible because ML models can utilize efficient vectorized computation to process a batch of request at a time. Batching is also necessary when your model is expensive to use and you want to maximize the utilization of hardware.
|
||||
|
||||
This guide teaches you how to:
|
||||
- use Serve's `@serve.batch` decorator
|
||||
- configure `@serve.batch` decorator
|
||||
|
||||
Machine Learning (ML) frameworks like Tensorflow, PyTorch, and Scikit-Learn support evaluating multiple samples at the same time.
|
||||
Ray Serve allows you to take advantage of this feature via dynamic request batching.
|
||||
When a request arrives, Serve puts the request in a queue. This queue buffers requests to form a batch sample. The batch is then be picked up by the model for evaluation. After the evaluation, the result batch will be split up, and each response is sent individually.
|
||||
|
||||
## Enable batching for your deployment
|
||||
You can enable batching by using the {mod}`ray.serve.batch` decorator. Let's take a look at an simple example by modifying the `MyModel` class to accept a batch.
|
||||
```{literalinclude} doc_code/batching_guide.py
|
||||
---
|
||||
start-after: __single_sample_begin__
|
||||
end-before: __single_sample_end__
|
||||
---
|
||||
```
|
||||
|
||||
The batching decorators expect you to make the following changes in your method signature:
|
||||
- The method is declared as an async method because the decorator batches in asyncio event loop.
|
||||
- The method accepts a list of its original input types as input. For example, `arg1: int, arg2: str` should be changed to `arg1: List[int], arg2: List[str]`.
|
||||
- The method returns a list. The length of the return list and the input list must be of equal lengths for the decorator to split the output evenly and return a corresponding response back to its respective request.
|
||||
|
||||
```{literalinclude} doc_code/batching_guide.py
|
||||
---
|
||||
start-after: __batch_begin__
|
||||
end-before: __batch_end__
|
||||
emphasize-lines: 6-9
|
||||
---
|
||||
```
|
||||
|
||||
You can supply two optional parameters to the decorators.
|
||||
- `batch_wait_timeout_s` controls how long Serve should wait for a batch once the first request arrives.
|
||||
- `max_batch_size` controls the size of the batch.
|
||||
Once the first request arrives, the batching decorator will wait for a full batch (up to `max_batch_size`) until `batch_wait_timeout_s` is reached. If the timeout is reached, the batch will be sent to the model regardless the batch size.
|
||||
|
||||
## Tips for fine-tuning batching parameters
|
||||
|
||||
`max_batch_size` ideally should be a power of 2 (2, 4, 8, 16, ...) because CPUs and GPUs are both optimized for data of these shapes. Large batch sizes incur a high memory cost as well as latency penalty for the first few requests.
|
||||
|
||||
`batch_wait_timeout_s` should be set considering the end to end latency SLO (Service Level Objective). After all, the first request could potentially this long for a full batch, adding to its latency cost. For example, if your latency target is 150ms, and the model takes 100ms to evaluate the batch, the `batch_wait_timeout_s` should be set to a value much lower than 150ms - 100ms = 50ms.
|
||||
|
||||
When using batching in a Serve Deployment Graph, the relationship between an upstream node and a downstream node might affect the performance as well. Consider a chain of two models where first model sets `max_batch_size=8` and second model sets `max_batch_size=6`. In this scenario, when the first model finishes a full batch of 8, the second model will finish one batch of 6 and then to fill the next batch, which will initially only be partially filled with 8 - 6 = 2 requests, incurring latency costs. The batch size of downstream models should ideally be multiples or divisors of the upstream models to ensure the batches play well together.
|
||||
|
|
@ -1,6 +1,6 @@
|
|||
(serve-dev-workflow)=
|
||||
|
||||
# Sample Development Workflow
|
||||
# Development Workflow
|
||||
|
||||
This page describes the recommended workflow for developing Ray Serve applications. If you're ready to go to production, jump to the [Production Guide](serve-in-production) section.
|
||||
|
||||
|
|
|
|||
|
|
@ -4,9 +4,9 @@
|
|||
|
||||
This tutorial will walk you through the process of deploying models with Ray Serve. It will show you how to
|
||||
|
||||
* expose your models over HTTP using Ray Serve [deployments](serve-managing-deployments-guide)
|
||||
* expose your models over HTTP using deployments
|
||||
* test your deployments over HTTP
|
||||
* compose multiple-model machine learning pipelines with Ray Serve [deployment graphs](serve-model-composition-guide)
|
||||
* compose multiple-model machine learning models together into a single application
|
||||
|
||||
We'll use two models in this tutorial:
|
||||
|
||||
|
|
@ -252,7 +252,7 @@ $ python graph_client.py
|
|||
c'était le meilleur des temps, c'était le pire des temps .
|
||||
```
|
||||
|
||||
Deployment graphs are useful since they let you deploy each part of your machine learning pipeline, such as inference and business logic steps, in separate deployments. Each of these deployments can be individually configured and scaled, ensuring you get maximal performance from your resources. See the guide on [model composition](serve-model-composition-guide) to learn more.
|
||||
Deployment graphs are useful since they let you deploy each part of your machine learning pipeline, such as inference and business logic steps, in separate deployments. Each of these deployments can be individually configured and scaled, ensuring you get maximal performance from your resources. See the guide on [model composition](serve-model-composition) to learn more.
|
||||
|
||||
## Next Steps
|
||||
|
||||
|
|
|
|||
|
|
@ -1,61 +0,0 @@
|
|||
(serve-handle-explainer)=
|
||||
|
||||
# ServeHandle: Calling Deployments from Python
|
||||
|
||||
[ServeHandle](serve-key-concepts-query-deployment) allows you to programmatically invoke your Serve deployments.
|
||||
|
||||
This is particularly useful for two use cases when:
|
||||
- calling deployments dynamically within the deployment graph.
|
||||
- iterating and testing your application in Python.
|
||||
|
||||
To use the ServeHandle, use {mod}`handle.remote <ray.serve.handle.RayServeHandle.remote>` to send requests to a deployment.
|
||||
These requests can be ordinary Python args and kwargs that are passed directly to the method. This returns a Ray `ObjectRef` whose result can be waited for or retrieved using `await` or `ray.get`.
|
||||
|
||||
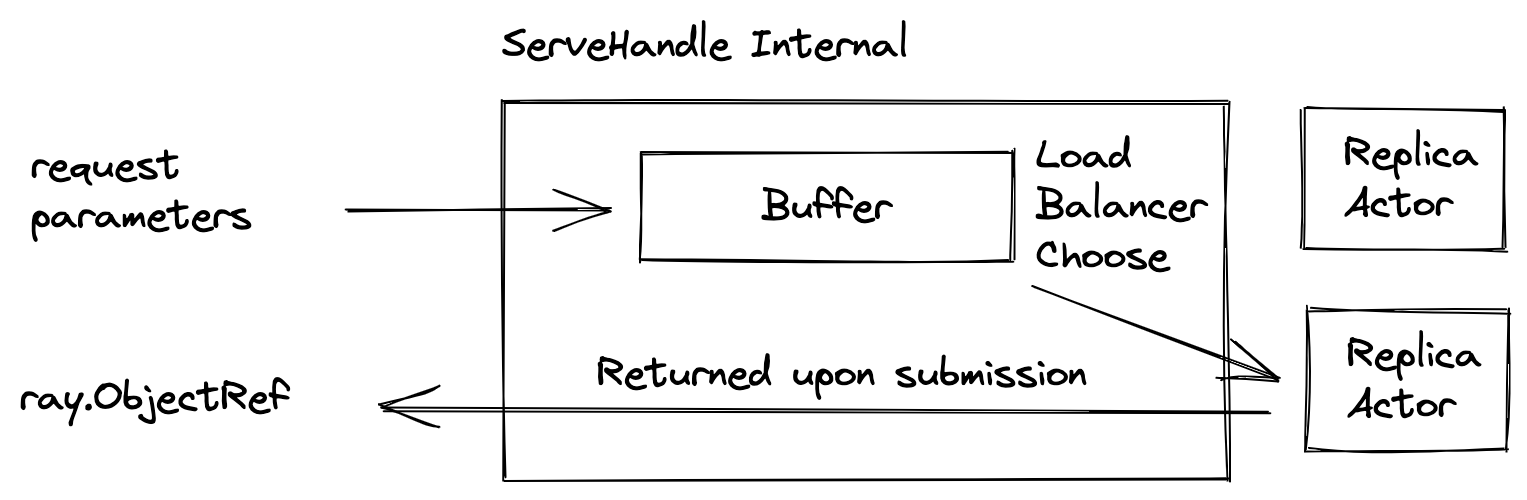
Conceptually, ServeHandle is a client side load balancer, routing requests to any replicas of a given deployment. Also, it performs buffering internally so it won't overwhelm the replicas.
|
||||
Using the current number of requests buffered, it informs the autoscaler to scale up the number of replicas.
|
||||
|
||||
|
||||
|
||||
ServeHandle takes request parameters and returns a future object of type [`ray.ObjectRef`](objects-in-ray), whose value will be filled with the result object. Because of the internal buffering, the time from submitting a request to getting a `ray.ObjectRef` varies from instantaneous to indefinitely long.
|
||||
|
||||
Because of this variability, we offer two types of handles to ensure the buffering period is handled efficiently. We offer synchronous and asynchronous versions of the handle:
|
||||
- `RayServeSyncHandle` directly returns a `ray.ObjectRef`. It blocks the current thread until the request is matched to a replica.
|
||||
- `RayServeDeploymentHandle` returns an `asyncio.Task` upon submission. The `asyncio.Task` can be awaited to resolve to a ray.ObjectRef. While the current request is buffered, other requests can be processed concurrently.
|
||||
|
||||
`serve.run` deploys a deployment graph and returns the entrypoint node’s handle (the node you passed as argument to `serve.run`). The return type is a `RayServeSyncHandle`. This is useful for interacting with and testing the newly created deployment graph.
|
||||
|
||||
```{literalinclude} ../serve/doc_code/handle_guide.py
|
||||
:start-after: __begin_sync_handle__
|
||||
:end-before: __end_sync_handle__
|
||||
:language: python
|
||||
```
|
||||
|
||||
In all other cases, `RayServeDeploymentHandle` is the default because the API is more performant than its blocking counterpart. For example, when implementing a dynamic dispatch node in deployment graph, the handle is asynchronous.
|
||||
|
||||
```{literalinclude} ../serve/doc_code/handle_guide.py
|
||||
:start-after: __begin_async_handle__
|
||||
:end-before: __end_async_handle__
|
||||
:language: python
|
||||
```
|
||||
|
||||
The result of `deployment_handle.remote()` can also be passed directly as an argument to other downstream handles, without having to await on it.
|
||||
|
||||
```{literalinclude} ../serve/doc_code/handle_guide.py
|
||||
:start-after: __begin_async_handle_chain__
|
||||
:end-before: __end_async_handle_chain__
|
||||
:language: python
|
||||
```
|
||||
|
||||
## Note about ray.ObjectRef
|
||||
|
||||
`ray.ObjectRef` corresponds to the result of a request submission. To retrieve the result, you can use the synchronous Ray Core API `ray.get(ref)` or the async API `await ref`. To wait for the result to be available without retrieving it, you can use the synchronous API `ray.wait([ref])` or the async API `await asyncio.wait([ref])`. You can mix and match these calls, but we recommend using async APIs to increase concurrency.
|
||||
|
||||
## Calling a specific method
|
||||
|
||||
In both types of ServeHandle, you can call a specific method by using the `.method_name` accessor. For example:
|
||||
|
||||
```{literalinclude} ../serve/doc_code/handle_guide.py
|
||||
:start-after: __begin_handle_method__
|
||||
:end-before: __end_handle_method__
|
||||
:language: python
|
||||
```
|
||||
|
|
@ -1,6 +1,6 @@
|
|||
# HTTP API
|
||||
# HTTP Handling
|
||||
|
||||
This section should help you understand how to:
|
||||
This section helps you understand how to:
|
||||
- send HTTP requests to Serve deployments
|
||||
- use Ray Serve to integrate with FastAPI
|
||||
- use customized HTTP Adapters
|
||||
|
|
|
|||
|
|
@ -21,7 +21,7 @@
|
|||
Ray Serve is a scalable model serving library for building online inference APIs.
|
||||
Serve is framework agnostic, so you can use a single toolkit to serve everything from deep learning models built with frameworks like PyTorch, Tensorflow, and Keras, to Scikit-Learn models, to arbitrary Python business logic.
|
||||
|
||||
Serve is particularly well suited for {ref}`serve-model-composition`, enabling you to build a complex inference service consisting of multiple ML models and business logic all in Python code.
|
||||
Serve is particularly well suited for [model composition](serve-model-composition), enabling you to build a complex inference service consisting of multiple ML models and business logic all in Python code.
|
||||
|
||||
Serve is built on top of Ray, so it easily scales to many machines and offers flexible scheduling support such as fractional GPUs so you can share resources and serve many machine learning models at low cost.
|
||||
|
||||
|
|
@ -242,8 +242,8 @@ or head over to the {doc}`tutorials/index` to get started building your Ray Serv
|
|||
|
||||
**User Guides**
|
||||
^^^
|
||||
Learn best practices for common patterns like :doc:`managing deployments <managing-deployments>`, how to call deployments :ref:`via HTTP <serve-http>` or :ref:`from Python <serve-handle-explainer>`.
|
||||
Learn how to serve multiple ML models with :ref:`Model Ensemble <serve-model-ensemble>`, and how to :ref:`monitor your Serve applications <serve-monitoring>`.
|
||||
Learn best practices for common patterns like :ref:`scaling and resource allocation <serve-scaling-and-resource-allocation>` and :ref:`model composition <serve-model-composition>`.
|
||||
Learn how to :ref:`develop Serve applications locally <serve-dev-workflow>` and :ref:`go to production <serve-in-production>`.
|
||||
|
||||
+++
|
||||
.. link-button:: serve-user-guides
|
||||
|
|
|
|||
|
|
@ -13,7 +13,7 @@ The number of replicas can be scaled up or down (or even autoscaled) to match th
|
|||
|
||||
To define a deployment, use the {mod}`@serve.deployment <ray.serve.api.deployment>` decorator on a Python class (or function for simple use cases).
|
||||
Then, `bind` the deployment with optional arguments to the constructor (see below).
|
||||
Finally, deploy the resulting "bound deployment" using `serve.run` (or the equivalent `serve run` CLI command).
|
||||
Finally, deploy the resulting "bound deployment" using `serve.run` (or the equivalent `serve run` CLI command, see [Development Workflow](serve-dev-workflow) for details).
|
||||
|
||||
```python
|
||||
@serve.deployment
|
||||
|
|
@ -120,8 +120,8 @@ Here's a simple example combining a preprocess function and model.
|
|||
```
|
||||
|
||||
## What's Next?
|
||||
Now that you have learned about the key concepts, you can dive into our [User Guides](user-guide) for more details about:
|
||||
- [Creating, updating, and deleting deployments](managing-deployments)
|
||||
- [Configuring HTTP ingress and integrating with FastAPI](http-guide)
|
||||
- [Composing deployments using ServeHandle](handle-guide)
|
||||
- [Building deployment graphs](serve-model-composition-deployment-graph)
|
||||
Now that you have learned the key concepts, you can dive into the [User Guide](user-guide):
|
||||
- [Scaling and allocating resources](scaling-and-resource-allocation)
|
||||
- [Configuring HTTP logic and integrating with FastAPI](http-guide)
|
||||
- [Development workflow for Serve applications](dev-workflow)
|
||||
- [Composing deployments to perform model composition](model_composition)
|
||||
|
|
|
|||
|
|
@ -1,55 +0,0 @@
|
|||
(serve-managing-deployments-guide)=
|
||||
|
||||
# Managing Deployments
|
||||
|
||||
This section should help you:
|
||||
|
||||
- create, query, update and configure deployments
|
||||
- configure resources of your deployments
|
||||
- specify different Python dependencies across different deployment using Runtime Environments
|
||||
|
||||
:::{tip}
|
||||
Get in touch with us if you're using or considering using [Ray Serve](https://docs.google.com/forms/d/1l8HT35jXMPtxVUtQPeGoe09VGp5jcvSv0TqPgyz6lGU).
|
||||
:::
|
||||
|
||||
```{contents}
|
||||
```
|
||||
|
||||
## Updating a Deployment
|
||||
|
||||
Often you want to be able to update your code or configuration options for a deployment over time.
|
||||
Deployments can be updated simply by updating the code or configuration options and calling `serve.run()` again.
|
||||
|
||||
```{literalinclude} ../serve/doc_code/managing_deployments.py
|
||||
:start-after: __updating_a_deployment_start__
|
||||
:end-before: __updating_a_deployment_end__
|
||||
:language: python
|
||||
```
|
||||
|
||||
By default, each call to `serve.run()` will cause a redeployment, even if the underlying code and options didn't change.
|
||||
This could be detrimental if you have many deployments in a script and and only want to update one: if you re-run the script, all of the deployments will be redeployed, not just the one you updated.
|
||||
To prevent this, you may provide a `version` string for the deployment as a keyword argument in the decorator or `Deployment.options()`.
|
||||
When a redeployment happens, Serve will perform a rolling update, bringing down at most 20% of the replicas at any given time.
|
||||
|
||||
(managing-deployments-user-configuration)=
|
||||
|
||||
## User Configuration
|
||||
|
||||
Suppose you want to update a parameter in your model without needing to restart
|
||||
the replicas in your deployment. You can do this by writing a `reconfigure` method
|
||||
for the class underlying your deployment. At runtime, you can then pass in your
|
||||
new parameters by setting the `user_config` option.
|
||||
|
||||
The following simple example will make the usage clear:
|
||||
|
||||
```{literalinclude} ../../../python/ray/serve/examples/doc/snippet_reconfigure.py
|
||||
```
|
||||
|
||||
The `reconfigure` method is called when the class is created if `user_config`
|
||||
is set. In particular, it's also called when new replicas are created in the
|
||||
future if scale up your deployment later. The `reconfigure` method is also called
|
||||
each time `user_config` is updated.
|
||||
|
||||
:::{note}
|
||||
The `user_config` and its contents must be JSON-serializable.
|
||||
:::
|
||||
|
|
@ -1,4 +1,8 @@
|
|||
# Managing Java Deployments
|
||||
# Experimental Java API
|
||||
|
||||
:::{warning}
|
||||
Java API support is an experimental feature and subject to change.
|
||||
:::
|
||||
|
||||
Java is a mainstream programming language for production services. Ray Serve offers a native Java API for creating, updating, and managing deployments. You can create Ray Serve deployments using Java and call them via Python, or vice versa.
|
||||
|
||||
|
|
|
|||
|
|
@ -1,8 +1,8 @@
|
|||
(serve-migration)=
|
||||
|
||||
# Serve 1.x to 2.x API Migration Guide
|
||||
# 1.x to 2.x API Migration Guide
|
||||
|
||||
This section is to help you migrate the deployment API from 1.x to 2.x.
|
||||
This section covers what to consider or change in your application when migrating from Ray versions 1.x to 2.x.
|
||||
|
||||
## What has been changed?
|
||||
|
||||
|
|
|
|||
|
|
@ -1,283 +0,0 @@
|
|||
(serve-ml-models)=
|
||||
# Serving ML Models
|
||||
|
||||
This section should help you:
|
||||
|
||||
- batch requests to optimize performance
|
||||
- serve multiple models by composing deployments
|
||||
- serve multiple models by making ensemble deployments
|
||||
|
||||
```{contents}
|
||||
```
|
||||
|
||||
(serve-batching)=
|
||||
|
||||
## Request Batching
|
||||
|
||||
You can also have Ray Serve batch requests for performance, which is especially important for some ML models that run on GPUs. In order to use this feature, you need to do the following two things:
|
||||
|
||||
1. Use `async def` for your request handling logic to process queries concurrently.
|
||||
2. Use the `@serve.batch` decorator to batch individual queries that come into the replica. The method/function that's decorated should handle a list of requests and return a list of the same length.
|
||||
|
||||
```{literalinclude} ../serve/doc_code/ml_models_examples.py
|
||||
:start-after: __batch_example_start__
|
||||
:end-before: __batch_example_end__
|
||||
:language: python
|
||||
```
|
||||
|
||||
Please take a look at [Batching Tutorial](serve-batch-tutorial) for a deep
|
||||
dive.
|
||||
|
||||
(serve-model-composition)=
|
||||
|
||||
## Model Composition
|
||||
|
||||
:::{note}
|
||||
Serve recently added an experimental API for building deployment graphs of multiple models.
|
||||
Please take a look at the [Deployment Graph API](serve-model-composition-deployment-graph) and try it out!
|
||||
:::
|
||||
|
||||
Ray Serve supports composing individually scalable models into a single model
|
||||
out of the box. For instance, you can combine multiple models to perform
|
||||
stacking or ensembles.
|
||||
|
||||
To define a higher-level composed model you need to do three things:
|
||||
|
||||
1. Define your underlying models (the ones that you will compose together) as
|
||||
Ray Serve deployments.
|
||||
2. Define your composed model, using the handles of the underlying models
|
||||
(see the example below).
|
||||
3. Define a deployment representing this composed model and query it!
|
||||
|
||||
In order to avoid synchronous execution in the composed model (e.g., it's very
|
||||
slow to make calls to the composed model), you'll need to make the function
|
||||
asynchronous by using an `async def`. You'll see this in the example below.
|
||||
|
||||
That's it. Let's take a look at an example:
|
||||
|
||||
```{literalinclude} ../../../python/ray/serve/examples/doc/snippet_model_composition.py
|
||||
```
|
||||
|
||||
(serve-model-ensemble)=
|
||||
|
||||
## Model Ensemble
|
||||
|
||||
Ray Serve supports creating different ensemble models
|
||||
|
||||
To define an ensemble of different models you need to do three things:
|
||||
|
||||
1. Define your underlying sub models (the ones that make up the ensemble) as
|
||||
Ray Serve deployments.
|
||||
2. Define your ensemble model, using the handles of the underlying models
|
||||
(see the example below).
|
||||
3. Define a deployment representing this ensemble model and query it!
|
||||
|
||||
In order to avoid synchronous execution in the ensemble model, you'll need to make
|
||||
the function asynchronous by using an `async def`. In contrast to a composition model,
|
||||
within an ensemble model, you want to call **all** sub models in parallel. This will be
|
||||
achieved by sending all prediction calls to the sub models via async by using
|
||||
`asyncio.wait()`. Each serve deployment used in an ensemble use case is independently
|
||||
scalable via changing `num_replicas`.
|
||||
|
||||
That's it. Let's take a look at an example:
|
||||
|
||||
```{literalinclude} ../../../python/ray/serve/examples/doc/snippet_model_ensemble.py
|
||||
```
|
||||
|
||||
## Integration with Model Registries
|
||||
|
||||
Ray Serve is flexible. If you can load your model as a Python
|
||||
function or class, then you can scale it up and serve it with Ray Serve.
|
||||
|
||||
For example, if you are using the
|
||||
[MLflow Model Registry](https://www.mlflow.org/docs/latest/model-registry.html)
|
||||
to manage your models, the following wrapper
|
||||
class will allow you to load a model using its MLflow `Model URI`:
|
||||
|
||||
```python
|
||||
import pandas as pd
|
||||
import mlflow.pyfunc
|
||||
|
||||
@serve.deployment
|
||||
class MLflowDeployment:
|
||||
def __init__(self, model_uri):
|
||||
self.model = mlflow.pyfunc.load_model(model_uri=model_uri)
|
||||
|
||||
async def __call__(self, request):
|
||||
csv_text = await request.body() # The body contains just raw csv text.
|
||||
df = pd.read_csv(csv_text)
|
||||
return self.model.predict(df)
|
||||
|
||||
model_uri = "model:/my_registered_model/Production"
|
||||
serve.run(MLflowDeployment.bind(model_uri))
|
||||
```
|
||||
|
||||
To serve multiple different MLflow models in the same program, use the `name` option:
|
||||
|
||||
```python
|
||||
serve.run(MLflowDeployment.options(name="my_mlflow_model_1").bind(model_uri))
|
||||
```
|
||||
|
||||
:::{tip}
|
||||
The above approach will work for any model registry, not just MLflow.
|
||||
Namely, load the model from the registry in `__init__`, and forward the request to the model in `__call__`.
|
||||
:::
|
||||
|
||||
For a complete hands-on and seamless integration with MLflow, try this self-contained example on your laptop.
|
||||
But first install `mlflow`.
|
||||
|
||||
```bash
|
||||
pip install mlflow
|
||||
```
|
||||
|
||||
```python
|
||||
# This brief example shows how to deploy models saved in a model registry such as
|
||||
# MLflow to Ray Serve, using the simple Ray Serve deployment APIs. You can peruse
|
||||
# the saved models' metrics and parameters in MLflow ui.
|
||||
#
|
||||
import json
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
import requests
|
||||
import os
|
||||
import tempfile
|
||||
|
||||
from sklearn.datasets import load_iris
|
||||
from sklearn.ensemble import GradientBoostingClassifier
|
||||
from mlflow.tracking import MlflowClient
|
||||
|
||||
from ray import serve
|
||||
import mlflow
|
||||
|
||||
|
||||
def create_and_save_model():
|
||||
# load Iris data
|
||||
iris_data = load_iris()
|
||||
data, target, target_names = (iris_data['data'],
|
||||
iris_data['target'],
|
||||
iris_data['target_names'])
|
||||
|
||||
# Instantiate a model
|
||||
model = GradientBoostingClassifier()
|
||||
|
||||
# Training and validation split
|
||||
np.random.shuffle(data), np.random.shuffle(target)
|
||||
train_x, train_y = data[:100], target[:100]
|
||||
val_x, val_y = data[100:], target[100:]
|
||||
|
||||
# Create labels list as file
|
||||
LABEL_PATH = os.path.join(tempfile.gettempdir(), "iris_labels.json")
|
||||
with open(LABEL_PATH, "w") as f:
|
||||
json.dump(target_names.tolist(), f)
|
||||
|
||||
# Train the model and save our label list as an MLflow artifact
|
||||
# mlflow.sklearn.autolog automatically logs all parameters and metrics during
|
||||
# the training.
|
||||
mlflow.sklearn.autolog()
|
||||
with mlflow.start_run() as run:
|
||||
model.fit(train_x, train_y)
|
||||
# Log label list as a artifact
|
||||
mlflow.log_artifact(LABEL_PATH, artifact_path="labels")
|
||||
return run.info.run_id
|
||||
|
||||
#
|
||||
# Create our Ray Serve deployment class
|
||||
#
|
||||
|
||||
|
||||
@serve.deployment(route_prefix="/regressor")
|
||||
class BoostingModel:
|
||||
def __init__(self, uri):
|
||||
# Load the model and label artifact from the local
|
||||
# Mlflow model registry as a PyFunc Model
|
||||
self.model = mlflow.pyfunc.load_model(model_uri=uri)
|
||||
|
||||
# Download the artifact list of labels
|
||||
local_dir = "/tmp/artifact_downloads"
|
||||
if not os.path.exists(local_dir):
|
||||
os.mkdir(local_dir)
|
||||
client = MlflowClient()
|
||||
local_path = f"{client.download_artifacts(run_id, 'labels', local_dir)}/iris_labels.json"
|
||||
with open(local_path, "r") as f:
|
||||
self.label_list = json.load(f)
|
||||
|
||||
async def __call__(self, starlette_request):
|
||||
payload = await starlette_request.json()
|
||||
print(f"Worker: received Starlette request with data: {payload}")
|
||||
|
||||
# Get the input vector from the payload
|
||||
input_vector = [
|
||||
payload["sepal length"],
|
||||
payload["sepal width"],
|
||||
payload["petal length"],
|
||||
payload["petal width"],
|
||||
]
|
||||
|
||||
# Convert the input vector in a Pandas DataFrame for prediction since
|
||||
# an MLflow PythonFunc model, model.predict(...), takes pandas DataFrame
|
||||
prediction = self.model.predict(pd.DataFrame([input_vector]))[0]
|
||||
human_name = self.label_list[prediction]
|
||||
return {"result": human_name}
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
# Train and save the model artifacts in MLflow.
|
||||
# Here our MLflow model registry is local file
|
||||
# directory ./mlruns
|
||||
run_id = create_and_save_model()
|
||||
|
||||
# Construct model uri to load the model from our model registry
|
||||
uri = f"runs:/{run_id}/model"
|
||||
# Deploy our model.
|
||||
serve.run(BoostingModel.bind(uri))
|
||||
|
||||
# Send in a request for labels types virginica, setosa, versicolor
|
||||
sample_request_inputs = [{
|
||||
"sepal length": 6.3,
|
||||
"sepal width": 3.3,
|
||||
"petal length": 6.0,
|
||||
"petal width": 2.5},
|
||||
{
|
||||
"sepal length": 5.1,
|
||||
"sepal width": 3.5,
|
||||
"petal length": 1.4,
|
||||
"petal width": 0.2},
|
||||
{
|
||||
"sepal length": 6.4,
|
||||
"sepal width": 3.2,
|
||||
"petal length": 4.5,
|
||||
"petal width": 1.5},
|
||||
]
|
||||
for input_request in sample_request_inputs:
|
||||
response = requests.get("http://localhost:8000/regressor",
|
||||
json=input_request)
|
||||
print(response.text)
|
||||
|
||||
print("Launch MLflow ui to see the model parameters, metrics, and artifacts: `mlflow ui` from current directory.")
|
||||
|
||||
#output
|
||||
#{
|
||||
# "result": "versicolor"
|
||||
#}
|
||||
#{
|
||||
# "result": "virginica"
|
||||
#}
|
||||
#{
|
||||
# "result": "setosa"
|
||||
#}
|
||||
#
|
||||
# Launch MLflow ui to see the model parameters, metrics, and artifacts: `mlflow ui` from current directory.
|
||||
```
|
||||
|
||||
For an even more hands-off and seamless integration with MLflow, check out the
|
||||
[Ray Serve MLflow deployment plugin](https://github.com/ray-project/mlflow-ray-serve). A full
|
||||
tutorial is available [here](https://github.com/mlflow/mlflow/tree/master/examples/ray_serve).
|
||||
|
||||
## Framework-Specific Tutorials
|
||||
|
||||
Ray Serve seamlessly integrates with popular Python ML libraries.
|
||||
Below are tutorials with some of these frameworks to help get you started.
|
||||
|
||||
- [Tensorflow, PyTorch, and Scikit-Learn Tutorials](serve-ml-models-tutorial)
|
||||
- [RLlib Tutorial](serve-rllib-tutorial)
|
||||
|
|
@ -1,4 +1,4 @@
|
|||
(serve-model-composition-guide)=
|
||||
(serve-model-composition)=
|
||||
|
||||
# Model Composition
|
||||
|
||||
|
|
@ -8,10 +8,17 @@ This section helps you:
|
|||
* independently scale and configure each of your ML models and business logic steps
|
||||
* connect your Ray Serve deployments together with the **deployment graph** API
|
||||
|
||||
(serve-model-composition-serve-handles)=
|
||||
## Calling Deployments using ServeHandles
|
||||
(serve-handle-explainer)=
|
||||
|
||||
You can call deployment methods from within other deployments using the {mod}`ServeHandle <ray.serve.handle.RayServeSyncHandle>`. This lets you divide your application's steps (such as preprocessing, model inference, and post-processing) into independent deployments that can be independently scaled and configured.
|
||||
## Composing Deployments using ServeHandles
|
||||
|
||||
You can call deployment methods from within other deployments using the [ServeHandle](serve-key-concepts-query-deployment). This lets you divide your application's steps (such as preprocessing, model inference, and post-processing) into independent deployments that can be independently scaled and configured.
|
||||
|
||||
To use the `ServeHandle`, use {mod}`handle.remote <ray.serve.handle.RayServeHandle.remote>` to send requests to a deployment.
|
||||
These requests can be ordinary Python args and kwargs that are passed directly to the method. This method call returns a Ray `ObjectRef` whose result can be waited for or retrieved using `await` or `ray.get`.
|
||||
|
||||
(serve-model-composition-serve-handles)=
|
||||
### Model Composition Example
|
||||
|
||||
Here's an example:
|
||||
|
||||
|
|
@ -72,8 +79,53 @@ Composition lets you break apart your application and independently scale each p
|
|||
With composition, you can avoid application-level bottlenecks when serving models and business logic steps that use different types and amounts of resources.
|
||||
:::
|
||||
|
||||
### ServeHandle Deep Dive
|
||||
|
||||
Conceptually, a `ServeHandle` is a client-side load balancer, routing requests to any replicas of a given deployment. Also, it performs buffering internally so it won't overwhelm the replicas.
|
||||
Using the current number of requests buffered, it informs the autoscaler to scale up the number of replicas.
|
||||
|
||||

|
||||
|
||||
`ServeHandle`s take request parameters and returns a future object of type [`ray.ObjectRef`](objects-in-ray), whose value will be filled with the result object. Because of the internal buffering, the time from submitting a request to getting a `ray.ObjectRef` can vary.
|
||||
|
||||
Because of this variability, Serve offers two types of handles to ensure the buffering period is handled efficiently. We offer synchronous and asynchronous versions of the handle:
|
||||
- `RayServeSyncHandle` directly returns a `ray.ObjectRef`. It blocks the current thread until the request is matched to a replica.
|
||||
- `RayServeDeploymentHandle` returns an `asyncio.Task` upon submission. The `asyncio.Task` can be awaited to resolve to a `ray.ObjectRef`. While the current request is buffered, other requests can be processed concurrently.
|
||||
|
||||
`serve.run` deploys a deployment graph and returns the entrypoint node’s handle (the node you passed as argument to `serve.run`). The return type is a `RayServeSyncHandle`. This is useful for interacting with and testing the newly created deployment graph.
|
||||
|
||||
```{literalinclude} ../serve/doc_code/handle_guide.py
|
||||
:start-after: __begin_sync_handle__
|
||||
:end-before: __end_sync_handle__
|
||||
:language: python
|
||||
```
|
||||
|
||||
In all other cases, `RayServeDeploymentHandle` is the default because the API is more performant than its blocking counterpart. For example, when implementing a dynamic dispatch node in deployment graph, the handle is asynchronous.
|
||||
|
||||
```{literalinclude} ../serve/doc_code/handle_guide.py
|
||||
:start-after: __begin_async_handle__
|
||||
:end-before: __end_async_handle__
|
||||
:language: python
|
||||
```
|
||||
|
||||
The result of `deployment_handle.remote()` can also be passed directly as an argument to other downstream handles, without having to await on it.
|
||||
|
||||
```{literalinclude} ../serve/doc_code/handle_guide.py
|
||||
:start-after: __begin_async_handle_chain__
|
||||
:end-before: __end_async_handle_chain__
|
||||
:language: python
|
||||
```
|
||||
|
||||
In both types of `ServeHandle`, you can call a specific method by using the `.method_name` accessor. For example:
|
||||
|
||||
```{literalinclude} ../serve/doc_code/handle_guide.py
|
||||
:start-after: __begin_handle_method__
|
||||
:end-before: __end_handle_method__
|
||||
:language: python
|
||||
```
|
||||
|
||||
:::{note}
|
||||
For a deep dive into the architecture of `ServeHandle` and its usage, take a look at [this user guide](serve-handle-explainer).
|
||||
`ray.ObjectRef` corresponds to the result of a request submission. To retrieve the result, you can use the synchronous Ray Core API `ray.get(ref)` or the async API `await ref`. To wait for the result to be available without retrieving it, you can use the synchronous API `ray.wait([ref])` or the async API `await asyncio.wait([ref])`. You can mix and match these calls, but we recommend using async APIs to increase concurrency.
|
||||
:::
|
||||
|
||||
(serve-model-composition-deployment-graph)=
|
||||
|
|
|
|||
|
|
@ -84,6 +84,51 @@ Check out [our benchmark workloads'](https://github.com/ray-project/ray/tree/f67
|
|||
You can check out our [microbenchmark instructions](https://github.com/ray-project/ray/blob/master/python/ray/serve/benchmarks/README.md)
|
||||
to benchmark Ray Serve on your hardware.
|
||||
|
||||
(serve-performance-batching-requests)=
|
||||
|
||||
## Request Batching
|
||||
|
||||
Serve offers a request batching feature that can improve your service throughput without sacrificing latency. This is possible because ML models can utilize efficient vectorized computation to process a batch of request at a time. Batching is also necessary when your model is expensive to use and you want to maximize the utilization of hardware.
|
||||
|
||||
Machine Learning (ML) frameworks such as Tensorflow, PyTorch, and Scikit-Learn support evaluating multiple samples at the same time.
|
||||
Ray Serve allows you to take advantage of this feature via dynamic request batching.
|
||||
When a request arrives, Serve puts the request in a queue. This queue buffers the requests to form a batch. The deployment picks up the batch and evaluates it. After the evaluation, the resulting batch will be split up, and each response is returned individually.
|
||||
|
||||
### Enable batching for your deployment
|
||||
You can enable batching by using the {mod}`ray.serve.batch` decorator. Let's take a look at a simple example by modifying the `MyModel` class to accept a batch.
|
||||
```{literalinclude} doc_code/batching_guide.py
|
||||
---
|
||||
start-after: __single_sample_begin__
|
||||
end-before: __single_sample_end__
|
||||
---
|
||||
```
|
||||
|
||||
The batching decorators expect you to make the following changes in your method signature:
|
||||
- The method is declared as an async method because the decorator batches in asyncio event loop.
|
||||
- The method accepts a list of its original input types as input. For example, `arg1: int, arg2: str` should be changed to `arg1: List[int], arg2: List[str]`.
|
||||
- The method returns a list. The length of the return list and the input list must be of equal lengths for the decorator to split the output evenly and return a corresponding response back to its respective request.
|
||||
|
||||
```{literalinclude} doc_code/batching_guide.py
|
||||
---
|
||||
start-after: __batch_begin__
|
||||
end-before: __batch_end__
|
||||
emphasize-lines: 6-9
|
||||
---
|
||||
```
|
||||
|
||||
You can supply two optional parameters to the decorators.
|
||||
- `batch_wait_timeout_s` controls how long Serve should wait for a batch once the first request arrives.
|
||||
- `max_batch_size` controls the size of the batch.
|
||||
Once the first request arrives, the batching decorator will wait for a full batch (up to `max_batch_size`) until `batch_wait_timeout_s` is reached. If the timeout is reached, the batch will be sent to the model regardless the batch size.
|
||||
|
||||
### Tips for fine-tuning batching parameters
|
||||
|
||||
`max_batch_size` ideally should be a power of 2 (2, 4, 8, 16, ...) because CPUs and GPUs are both optimized for data of these shapes. Large batch sizes incur a high memory cost as well as latency penalty for the first few requests.
|
||||
|
||||
`batch_wait_timeout_s` should be set considering the end to end latency SLO (Service Level Objective). For example, if your latency target is 150ms, and the model takes 100ms to evaluate the batch, the `batch_wait_timeout_s` should be set to a value much lower than 150ms - 100ms = 50ms.
|
||||
|
||||
When using batching in a Serve Deployment Graph, the relationship between an upstream node and a downstream node might affect the performance as well. Consider a chain of two models where first model sets `max_batch_size=8` and second model sets `max_batch_size=6`. In this scenario, when the first model finishes a full batch of 8, the second model will finish one batch of 6 and then to fill the next batch, which will initially only be partially filled with 8 - 6 = 2 requests, incurring latency costs. The batch size of downstream models should ideally be multiples or divisors of the upstream models to ensure the batches play well together.
|
||||
|
||||
## Debugging performance issues
|
||||
|
||||
The performance issue you're most likely to encounter is high latency and/or low throughput for requests.
|
||||
|
|
@ -110,28 +155,3 @@ hitting the same queuing issue mentioned above, you might want to increase
|
|||
`max_concurrent_queries`. Serve sets a low number (100) by default so the client gets
|
||||
proper backpressure. You can increase the value in the deployment decorator; e.g.
|
||||
`@serve.deployment(max_concurrent_queries=1000)`.
|
||||
|
||||
(serve-performance-batching-requests)=
|
||||
### Batching requests
|
||||
|
||||
If your deployment can process batches at a sublinear latency
|
||||
(meaning, for example, that it takes say 1ms to process 1 query and 5ms to process 10 of them)
|
||||
then batching is your best approach. Check out the [batching guide](serve-batching) and
|
||||
refactor your deployment to accept batches (especially for GPU-based ML inference). You might want to tune `max_batch_size` and `batch_wait_timeout` in the `@serve.batch` decorator to maximize the benefits:
|
||||
|
||||
- `max_batch_size` specifies how big the batch should be. Generally,
|
||||
we recommend choosing the largest batch size your function can handle
|
||||
without losing the sublinear performance improvement.
|
||||
For example, suppose it takes 1ms to process 1 query, 5ms to process 10 queries,
|
||||
and 6ms to process 11 queries. Here you should set the batch size to 10
|
||||
because adding more queries won’t improve the performance.
|
||||
- `batch_wait_timeout` specifies the maximum amount of time to wait before
|
||||
a batch should be processed, even if it’s not full. It should be set according
|
||||
to the equation:
|
||||
|
||||
```
|
||||
batch_wait_timeout + full batch processing time ~= expected latency
|
||||
```
|
||||
|
||||
The larger that `batch_wait_timeout` is, the more full the typical batch will be.
|
||||
To maximize throughput, you should set `batch_wait_timeout` as large as possible without exceeding your desired expected latency in the equation above.
|
||||
|
|
|
|||
|
|
@ -206,7 +206,7 @@ Lightweight config updates are only possible for deployments that are included a
|
|||
:::
|
||||
|
||||
### Updating User Config
|
||||
Let's use the `FruitStand` deployment graph [from an earlier section](fruit-config-yaml) as an example. All the individual fruit deployments contain a `reconfigure()` method. [This method allows us to issue lightweight updates](managing-deployments-user-configuration) to our deployments by updating the `user_config`.
|
||||
Let's use the `FruitStand` deployment graph [from an earlier section](fruit-config-yaml) as an example. All the individual fruit deployments contain a `reconfigure()` method. This method allows us to issue lightweight updates to our deployments by updating the `user_config`.
|
||||
|
||||
First let's deploy the graph. Make sure to stop any previous Ray cluster using the CLI command `ray stop` for this example:
|
||||
|
||||
|
|
|
|||
|
|
@ -1,5 +0,0 @@
|
|||
# Serving Ray AIR Checkpoints
|
||||
|
||||
[Ray AI Runtime (AIR)](air) is a scalable and unified toolkit for ML applications. Ray Serve is part of Ray AIR.
|
||||
It natively integrates with AIR's `Predictor` and `Checkpoint` abstractions to enable seamless transition from training to serving.
|
||||
You can learn more about how to serve Ray AIR Checkpoints in [this guide](air-serving-guide).
|
||||
|
|
@ -1,3 +1,5 @@
|
|||
(serve-scaling-and-resource-allocation)=
|
||||
|
||||
# Scaling and Resource Allocation
|
||||
|
||||
This guide helps you to:
|
||||
|
|
|
|||
|
|
@ -56,7 +56,7 @@ $ serve run demo:app
|
|||
Now you can access your Gradio app at `http://localhost:8000`! This is what it should look like:
|
||||
|
||||
|
||||
See [Putting Ray Serve Deployment Graphs in Production](serve-in-production) for more information on how to deploy your app in production.
|
||||
See the [Production Guide](serve-in-production) for more information on how to deploy your app in production.
|
||||
|
||||
|
||||
## Parallelizing models with Ray Serve
|
||||
|
|
@ -120,4 +120,4 @@ $ serve run demo:app
|
|||
Access your Gradio app at `http://localhost:8000`, and you should see the following interactive interface:
|
||||
|
||||
|
||||
See [Putting Ray Serve Deployment Graphs in Production](serve-in-production) for more information on how to deploy your app in production.
|
||||
See the [Production Guide](serve-in-production) for more information on how to deploy your app in production.
|
||||
|
|
|
|||
|
|
@ -94,7 +94,7 @@ class ServePPOModel:
|
|||
|
||||
:::{tip}
|
||||
Although we used a single input and `Algorithm.compute_single_action(...)` here, you
|
||||
can process a batch of input using Ray Serve's [batching](serve-batching) feature
|
||||
can process a batch of input using Ray Serve's [batching](serve-performance-batching-requests) feature
|
||||
and use `Algorithm.compute_actions(...)` to process a batch of inputs.
|
||||
:::
|
||||
|
||||
|
|
|
|||
|
|
@ -3,18 +3,11 @@
|
|||
|
||||
If you’re new to Ray Serve, we recommend starting with the [Ray Serve Quick Start](getting_started).
|
||||
|
||||
This user guide will help you navigate the Ray Serve project and show you how achieve several tasks. For instance
|
||||
you will learn:
|
||||
|
||||
- [Handling Dependencies](handling-dependencies)
|
||||
This user guide will help you navigate the Ray Serve project and show you how to achieve several key tasks:
|
||||
- [HTTP Handling](http-guide)
|
||||
- [Scaling and Resource Allocation](scaling-and-resource-allocation)
|
||||
- [Configuring HTTP and Bring Your own FastAPI app](http-guide)
|
||||
- [Using HTTP Adapters](http-guide)
|
||||
- [Composing Deployments](handle-guide)
|
||||
- [Serving Ray AIR Checkpoints](ray-air-serve-guide)
|
||||
- [Serving ML Models](ml-models)
|
||||
- [Use Request Batching](batching-guide)
|
||||
- [Using Deployment Graphs](serve-model-composition-deployment-graph)
|
||||
- [Model Composition](serve-model-composition)
|
||||
- [Development Workflow](dev-workflow)
|
||||
- [Production Guide](serve-in-production)
|
||||
- [Monitoring Ray Serve](serve-monitoring)
|
||||
- [Performance Tuning](performance)
|
||||
- [Handling Dependencies](handling-dependencies)
|
||||
|
|
|
|||
Loading…
Add table
Reference in a new issue