mirror of
https://github.com/vale981/ray
synced 2025-03-06 02:21:39 -05:00
[Serve][Doc] Rewrite the ServeHandle page (#27775)
This commit is contained in:
parent
75d13faa50
commit
4be232e413
4 changed files with 152 additions and 68 deletions
|
|
@ -1,9 +1,107 @@
|
||||||
|
# flake8: noqa
|
||||||
|
|
||||||
|
# __begin_sync_handle__
|
||||||
import ray
|
import ray
|
||||||
from ray import serve
|
from ray import serve
|
||||||
import requests
|
from ray.serve.handle import RayServeSyncHandle
|
||||||
|
|
||||||
|
|
||||||
|
@serve.deployment
|
||||||
|
class Model:
|
||||||
|
def __call__(self):
|
||||||
|
return "hello"
|
||||||
|
|
||||||
|
|
||||||
|
handle: RayServeSyncHandle = serve.run(Model.bind())
|
||||||
|
ref: ray.ObjectRef = handle.remote() # blocks until request is assigned to replica
|
||||||
|
assert ray.get(ref) == "hello"
|
||||||
|
# __end_sync_handle__
|
||||||
|
|
||||||
|
# __begin_async_handle__
|
||||||
|
import asyncio
|
||||||
|
import random
|
||||||
|
import ray
|
||||||
|
from ray import serve
|
||||||
|
from ray.serve.handle import RayServeDeploymentHandle, RayServeSyncHandle
|
||||||
|
|
||||||
|
|
||||||
|
@serve.deployment
|
||||||
|
class Model:
|
||||||
|
def __call__(self):
|
||||||
|
return "hello"
|
||||||
|
|
||||||
|
|
||||||
|
@serve.deployment
|
||||||
|
class DynamicDispatcher:
|
||||||
|
def __init__(
|
||||||
|
self, handle_a: RayServeDeploymentHandle, handle_b: RayServeDeploymentHandle
|
||||||
|
):
|
||||||
|
self.handle_a = handle_a
|
||||||
|
self.handle_b = handle_b
|
||||||
|
|
||||||
|
async def __call__(self):
|
||||||
|
handle_chosen = self.handle_a if random.random() < 0.5 else self.handle_b
|
||||||
|
|
||||||
|
# The request is enqueued.
|
||||||
|
submission_task: asyncio.Task = handle_chosen.remote()
|
||||||
|
# The request is assigned to a replica.
|
||||||
|
ref: ray.ObjectRef = await submission_task
|
||||||
|
# The request has been processed by the replica.
|
||||||
|
result = await ref
|
||||||
|
|
||||||
|
return result
|
||||||
|
|
||||||
|
|
||||||
|
handle: RayServeSyncHandle = serve.run(
|
||||||
|
DynamicDispatcher.bind(Model.bind(), Model.bind())
|
||||||
|
)
|
||||||
|
ref: ray.ObjectRef = handle.remote()
|
||||||
|
assert ray.get(ref) == "hello"
|
||||||
|
|
||||||
|
# __end_async_handle__
|
||||||
|
|
||||||
|
# __begin_async_handle_chain__
|
||||||
|
import asyncio
|
||||||
|
import ray
|
||||||
|
from ray import serve
|
||||||
|
from ray.serve.handle import RayServeDeploymentHandle, RayServeSyncHandle
|
||||||
|
|
||||||
|
|
||||||
|
@serve.deployment
|
||||||
|
class Model:
|
||||||
|
def __call__(self, inp):
|
||||||
|
return "hello " + inp
|
||||||
|
|
||||||
|
|
||||||
|
@serve.deployment
|
||||||
|
class Chain:
|
||||||
|
def __init__(
|
||||||
|
self, handle_a: RayServeDeploymentHandle, handle_b: RayServeDeploymentHandle
|
||||||
|
):
|
||||||
|
self.handle_a = handle_a
|
||||||
|
self.handle_b = handle_b
|
||||||
|
|
||||||
|
async def __call__(self, inp):
|
||||||
|
ref: asyncio.Task = await self.handle_b.remote(
|
||||||
|
# Serve can handle enqueued-task as dependencies.
|
||||||
|
self.handle_a.remote(inp)
|
||||||
|
)
|
||||||
|
return await ref
|
||||||
|
|
||||||
|
|
||||||
|
handle: RayServeSyncHandle = serve.run(Chain.bind(Model.bind(), Model.bind()))
|
||||||
|
ref: ray.ObjectRef = handle.remote("Serve")
|
||||||
|
assert ray.get(ref) == "hello hello Serve"
|
||||||
|
|
||||||
|
# __end_async_handle_chain__
|
||||||
|
|
||||||
|
|
||||||
|
# __begin_handle_method__
|
||||||
|
import ray
|
||||||
|
from ray import serve
|
||||||
|
from ray.serve.handle import RayServeSyncHandle
|
||||||
|
|
||||||
|
|
||||||
# __basic_example_start__
|
|
||||||
@serve.deployment
|
@serve.deployment
|
||||||
class Deployment:
|
class Deployment:
|
||||||
def method1(self, arg):
|
def method1(self, arg):
|
||||||
|
|
@ -13,32 +111,9 @@ class Deployment:
|
||||||
return f"__call__: {arg}"
|
return f"__call__: {arg}"
|
||||||
|
|
||||||
|
|
||||||
handle = serve.run(Deployment.bind())
|
handle: RayServeSyncHandle = serve.run(Deployment.bind())
|
||||||
|
|
||||||
ray.get(handle.remote("hi")) # Defaults to calling the __call__ method.
|
ray.get(handle.remote("hi")) # Defaults to calling the __call__ method.
|
||||||
ray.get(handle.method1.remote("hi")) # Call a different method.
|
ray.get(handle.method1.remote("hi")) # Call a different method.
|
||||||
# __basic_example_end__
|
|
||||||
|
|
||||||
|
# __end_handle_method__
|
||||||
# __async_handle_start__
|
|
||||||
@serve.deployment(route_prefix="/api")
|
|
||||||
class Deployment:
|
|
||||||
def say_hello(self, name: str):
|
|
||||||
return f"Hello {name}!"
|
|
||||||
|
|
||||||
def __call__(self, request):
|
|
||||||
return self.say_hello(request.query_params["name"])
|
|
||||||
|
|
||||||
|
|
||||||
handle = serve.run(Deployment.bind())
|
|
||||||
|
|
||||||
# __async_handle_end__
|
|
||||||
|
|
||||||
|
|
||||||
# __async_handle_print_start__
|
|
||||||
print(requests.get("http://localhost:8000/api?name=Alice"))
|
|
||||||
# Hello Alice!
|
|
||||||
|
|
||||||
print(ray.get(handle.say_hello.remote("Alice")))
|
|
||||||
# Hello Alice!
|
|
||||||
# __async_handle_print_end__
|
|
||||||
|
|
|
||||||
|
|
@ -2,55 +2,60 @@
|
||||||
|
|
||||||
# ServeHandle: Calling Deployments from Python
|
# ServeHandle: Calling Deployments from Python
|
||||||
|
|
||||||
Ray Serve enables you to query models both from HTTP and Python. This feature
|
[ServeHandle](serve-key-concepts-query-deployment) allows you to programmatically invoke your Serve deployments.
|
||||||
enables seamless [model composition](serve-model-composition-guide). You can
|
|
||||||
get a `ServeHandle` corresponding to deployment, similar how you can
|
|
||||||
reach a deployment through HTTP via a specific route. When you issue a request
|
|
||||||
to a deployment through `ServeHandle`, the request is load balanced across
|
|
||||||
available replicas in the same way an HTTP request is.
|
|
||||||
|
|
||||||
To call a Ray Serve deployment from python, use {mod}`Deployment.get_handle <ray.serve.api.Deployment>`
|
This is particularly useful for two use cases when:
|
||||||
to get a handle to the deployment, then use
|
- calling deployments dynamically within the deployment graph.
|
||||||
{mod}`handle.remote <ray.serve.handle.RayServeHandle.remote>` to send requests
|
- iterating and testing your application in Python.
|
||||||
to that deployment. These requests can pass ordinary args and kwargs that are
|
|
||||||
passed directly to the method. This returns a Ray `ObjectRef` whose result
|
To use the ServeHandle, use {mod}`handle.remote <ray.serve.handle.RayServeHandle.remote>` to send requests to a deployment.
|
||||||
can be waited for or retrieved using `ray.wait` or `ray.get`.
|
These requests can be ordinary Python args and kwargs that are passed directly to the method. This returns a Ray `ObjectRef` whose result can be waited for or retrieved using `await` or `ray.get`.
|
||||||
|
|
||||||
|
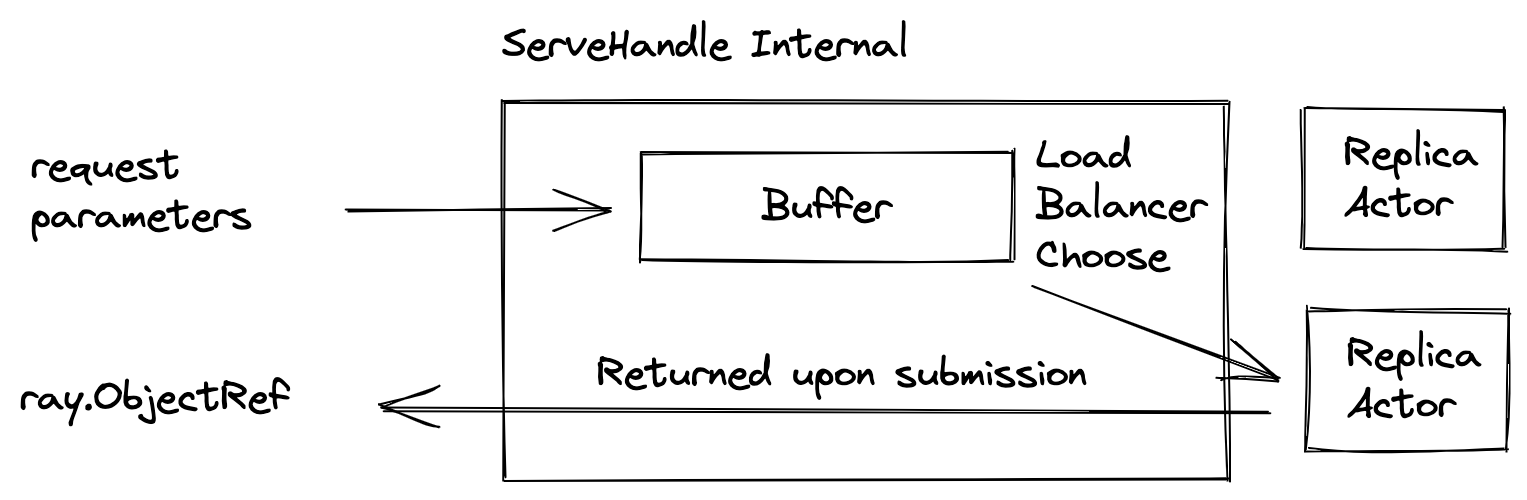
Conceptually, ServeHandle is a client side load balancer, routing requests to any replicas of a given deployment. Also, it performs buffering internally so it won't overwhelm the replicas.
|
||||||
|
Using the current number of requests buffered, it informs the autoscaler to scale up the number of replicas.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
ServeHandle takes request parameters and returns a future object of type [`ray.ObjectRef`](objects-in-ray), whose value will be filled with the result object. Because of the internal buffering, the time from submitting a request to getting a `ray.ObjectRef` varies from instantaneous to indefinitely long.
|
||||||
|
|
||||||
|
Because of this variability, we offer two types of handles to ensure the buffering period is handled efficiently. We offer synchronous and asynchronous versions of the handle:
|
||||||
|
- `RayServeSyncHandle` directly returns a `ray.ObjectRef`. It blocks the current thread until the request is matched to a replica.
|
||||||
|
- `RayServeDeploymentHandle` returns an `asyncio.Task` upon submission. The `asyncio.Task` can be awaited to resolve to a ray.ObjectRef. While the current request is buffered, other requests can be processed concurrently.
|
||||||
|
|
||||||
|
`serve.run` deploys a deployment graph and returns the entrypoint node’s handle (the node you passed as argument to `serve.run`). The return type is a `RayServeSyncHandle`. This is useful for interacting with and testing the newly created deployment graph.
|
||||||
|
|
||||||
```{literalinclude} ../serve/doc_code/handle_guide.py
|
```{literalinclude} ../serve/doc_code/handle_guide.py
|
||||||
:start-after: __basic_example_start__
|
:start-after: __begin_sync_handle__
|
||||||
:end-before: __basic_example_end__
|
:end-before: __end_sync_handle__
|
||||||
:language: python
|
:language: python
|
||||||
```
|
```
|
||||||
|
|
||||||
If you want to use the same deployment to serve both HTTP and ServeHandle traffic, the recommended best practice is to define an internal method that the HTTP handling logic will call:
|
In all other cases, `RayServeDeploymentHandle` is the default because the API is more performant than its blocking counterpart. For example, when implementing a dynamic dispatch node in deployment graph, the handle is asynchronous.
|
||||||
|
|
||||||
```{literalinclude} ../serve/doc_code/handle_guide.py
|
```{literalinclude} ../serve/doc_code/handle_guide.py
|
||||||
:start-after: __async_handle_start__
|
:start-after: __begin_async_handle__
|
||||||
:end-before: __async_handle_end__
|
:end-before: __end_async_handle__
|
||||||
:language: python
|
:language: python
|
||||||
```
|
```
|
||||||
|
|
||||||
Now we can invoke the same logic from both HTTP or Python:
|
The result of `deployment_handle.remote()` can also be passed directly as an argument to other downstream handles, without having to await on it.
|
||||||
|
|
||||||
```{literalinclude} ../serve/doc_code/handle_guide.py
|
```{literalinclude} ../serve/doc_code/handle_guide.py
|
||||||
:start-after: __async_handle_print_start__
|
:start-after: __begin_async_handle_chain__
|
||||||
:end-before: __async_handle_print_end__
|
:end-before: __end_async_handle_chain__
|
||||||
:language: python
|
:language: python
|
||||||
```
|
```
|
||||||
|
|
||||||
(serve-sync-async-handles)=
|
## Note about ray.ObjectRef
|
||||||
|
|
||||||
## Sync and Async Handles
|
`ray.ObjectRef` corresponds to the result of a request submission. To retrieve the result, you can use the synchronous Ray Core API `ray.get(ref)` or the async API `await ref`. To wait for the result to be available without retrieving it, you can use the synchronous API `ray.wait([ref])` or the async API `await asyncio.wait([ref])`. You can mix and match these calls, but we recommend using async APIs to increase concurrency.
|
||||||
|
|
||||||
Ray Serve offers two types of `ServeHandle`. You can use the `Deployment.get_handle(..., sync=True|False)`
|
## Calling a specific method
|
||||||
flag to toggle between them.
|
|
||||||
|
|
||||||
- When you set `sync=True` (the default), a synchronous handle is returned.
|
In both types of ServeHandle, you can call a specific method by using the `.method_name` accessor. For example:
|
||||||
Calling `handle.remote()` should return a Ray `ObjectRef`.
|
|
||||||
- When you set `sync=False`, an asyncio based handle is returned. You need to
|
|
||||||
Call it with `await handle.remote()` to return a Ray ObjectRef. To use `await`,
|
|
||||||
you have to run `Deployment.get_handle` and `handle.remote` in Python asyncio event loop.
|
|
||||||
|
|
||||||
The async handle has performance advantage because it uses asyncio directly; as compared
|
```{literalinclude} ../serve/doc_code/handle_guide.py
|
||||||
to the sync handle, which talks to an asyncio event loop in a thread. To learn more about
|
:start-after: __begin_handle_method__
|
||||||
the reasoning behind these, checkout our [architecture documentation](serve-architecture).
|
:end-before: __end_handle_method__
|
||||||
|
:language: python
|
||||||
|
```
|
||||||
|
|
@ -11,7 +11,7 @@ This section helps you:
|
||||||
(serve-model-composition-serve-handles)=
|
(serve-model-composition-serve-handles)=
|
||||||
## Calling Deployments using ServeHandles
|
## Calling Deployments using ServeHandles
|
||||||
|
|
||||||
You can call deployment methods from within other deployments using the {mod}`ServeHandle <ray.serve.handle.RayServeHandle>`. This lets you divide your application's steps (such as preprocessing, model inference, and post-processing) into independent deployments that can be independently scaled and configured.
|
You can call deployment methods from within other deployments using the {mod}`ServeHandle <ray.serve.handle.RayServeSyncHandle>`. This lets you divide your application's steps (such as preprocessing, model inference, and post-processing) into independent deployments that can be independently scaled and configured.
|
||||||
|
|
||||||
Here's an example:
|
Here's an example:
|
||||||
|
|
||||||
|
|
@ -72,6 +72,10 @@ Composition lets you break apart your application and independently scale each p
|
||||||
With composition, you can avoid application-level bottlenecks when serving models and business logic steps that use different types and amounts of resources.
|
With composition, you can avoid application-level bottlenecks when serving models and business logic steps that use different types and amounts of resources.
|
||||||
:::
|
:::
|
||||||
|
|
||||||
|
```{note}
|
||||||
|
For a deep dive in to the architecture of ServeHandle and its usage, take a look at [this user guide](serve-handle-explainer).
|
||||||
|
```
|
||||||
|
|
||||||
(serve-model-composition-deployment-graph)=
|
(serve-model-composition-deployment-graph)=
|
||||||
## Deployment Graph API
|
## Deployment Graph API
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -304,7 +304,7 @@ If you start Ray and deploy your deployment graph from a directory that doesn't
|
||||||
|
|
||||||
To make your config file location-independent, you can push your deployment graph code to [a remote repository and add that repository to your config file's `runtime_env` field](remote-uris). When Serve runs your deployment graph, it will pull the code from the remote repository rather than use a local copy. **This is a best practice** because it lets you deploy your config file from any machine in any directory and share the file with other developers, making it a more standalone artifact.
|
To make your config file location-independent, you can push your deployment graph code to [a remote repository and add that repository to your config file's `runtime_env` field](remote-uris). When Serve runs your deployment graph, it will pull the code from the remote repository rather than use a local copy. **This is a best practice** because it lets you deploy your config file from any machine in any directory and share the file with other developers, making it a more standalone artifact.
|
||||||
|
|
||||||
As an example, we have [pushed a copy of the FruitStand deployment graph to GitHub](https://github.com/ray-project/test_dag/blob/c620251044717ace0a4c19d766d43c5099af8a77/fruit.py). You can use this config file to deploy the `FruitStand` deployment graph to your own Ray cluster even if you don't have the code locally:
|
As an example, we have [pushed a copy of the FruitStand deployment graph to GitHub](https://github.com/ray-project/test_dag/blob/40d61c141b9c37853a7014b8659fc7f23c1d04f6/fruit.py). You can use this config file to deploy the `FruitStand` deployment graph to your own Ray cluster even if you don't have the code locally:
|
||||||
|
|
||||||
```yaml
|
```yaml
|
||||||
import_path: fruit.deployment_graph
|
import_path: fruit.deployment_graph
|
||||||
|
|
|
||||||
Loading…
Add table
Reference in a new issue